지난 글에서 소개한 블루스카이는 자신들의 프로토콜의 API를 공개했고, 몇 달 전부터 정책 변경으로 개발자 API로 월 5,000불을 요구하는 트위터와는 달리 무료로 사용이 가능합니다. (구체적인 rate limit은 아직은 정해지지 않은 것 같지만, 비정상적인 호출은 블루스카이 개발자 측에서 모니터링 후 제재를 가할 수 있습니다) 이번 글에서는 파이썬으로 포스트를 작성하는 봇을 만들고, 자동화 스케줄링하는 것까지 다뤄보고자 합니다. 파이썬에는 어느 정도 익숙하지만 AWS 같은 클라우드 서비스를 통한 자동화에는 익숙하지 않은 독자를 상정하였음을 밝힙니다.
(최종 업데이트: 2023년 7월 25일)
1. 포스트 올리는 함수 만들기
블루스카이 API, 엄밀히 말해 AT Protocol API는 서버에 요청을 하면 그에 맞는 결과를 가져올 수 있게끔 도와주는 규약입니다. 표준적인 형태는 Typescript를 이용해 구현이 되어있으며 깃허브에서 확인할 수 있습니다만, 애초에 그 코어는 uri 기반으로 요청을 보내는 형태라 다른 많은 언어로도 구현이 이루어지고 있습니다. AT Protocol의 Community Projects를 통해 그 결과물들을 확인할 수 있습니다.
파이썬의 경우 atprototools 같이 pip로 설치해서 무난하게 쓸 수 있는 라이브러리도 찾아볼 수 있습니다. 첫 페이지의 간단한 예시들로 어떻게 포스트를 쓰고, 특정 계정의 포스트들을 받아오고, 답글을 달 수 있는지 감을 잡을 수 있을 것입니다. 다만 이 라이브러리의 경우 원래 주어진 API의 모든 기능을 활용하고 있지는 않기 때문에, 주어진 것들을 십분활용하기 위해서는 구체적으로 어떤 스펙으로 규정되어 있는지를 알아야 할 필요가 있을 수 있습니다. 이에 대해서는 Protocol Overview 페이지에서 확인할 수 있습니다.
네이버나 알라딘, 한국은행 등 자사가 퍼블리시하는 정보를 API 형태로 받아올 수 있게 오픈API를 제공하는 경우 그를 활용해 정보를 받아올 수 있죠. 이에 대해서는 이미 많은 정보글들이 있기 떄문에 생략합니다. (네이버 뉴스에서 특정 키워드로 검색해서 텔레그램 뉴스 봇 만들기 같은 글들 찾아보면 도움이 될 것 같습니다. 아래 “더 읽어볼 것들”에서 예시를 몇 가지 수록했습니다) 이 포스트에서는 간단한 예시로, 실행하면 그 시점의 시각을 포스트로 표시하는 함수를 만들어 봅시다.
import datetime
from atprototools import Session
# 아래 두 값은 환경변수로 지정하는 것이 더 안전합니다
USERNAME = '핸들'
PASSWORD = '앱패스워드'
session = Session(USERNAME, PASSWORD)
def post():
now = datetime.datetime.now()
year, month, day, hour, minute, second = now.year, now.month, now.day, now.hour, now.minute, now.second
days = ['월', '화', '수', '목', '금', '토', '일']
if hour == 0:
# 0시에서 1시 사이에는 연월일과 요일까지 나오도록
message = f"[자동] 현재 시각은 {year}년 {month}월 {day}일 {days[day]}요일 {hour}시 {minute}분입니다."
if day == 0:
# 월요일 0시에서 1시에는 탄식을 붙여서
message += " 월요일......"
else:
# 1시 이후는 시와 분만
message = f"[자동] 현재 시각은 {hour}시 {minute}분입니다."
if day < 5 and hour == 18:
# 주중 오후 6시에서 7시 사이에는 칼퇴를 기원하며
message += " 퇴근하자!!"
# atprotools 0.15 버전 기준 메서드 호출
session.post_bloot(message)
사실상 마지막 한 줄 하나로 포스트가 작성되는 셈입니다. 간단하지요.
이 함수를 실행하면 그 시점에서의 정보를 바탕으로 포스트 형태로 가공하고, 필요에 따라 이미지나 링크를 첨부한 후, AT Protocol API를 통해 포스트가 올라가도록 요청을 할 수 있습니다. 앞서 언급드렸다시피 오픈API로 외부 정보를 포스트로 만들 수도 있고, 기존 트위터에서의 봇들처럼 트윗으로 쓸 내용들을 미리 테이블화해 이걸 랜덤으로 혹은 순차적으로 포스트하도록 만드는 것도 가능하죠. 아직은 자동화에 대해 생각하지 마시고, 함수를 실행하는 순간 그 시점에서 정보들을 얻어 포스트로 만드는 함수를 짜보도록 합니다.
2. 클라우드에서 실행하기 위한 사전 지식
만약 집에서 24시간 돌아가는 컴퓨터나 서버가 있다면 그 환경에서 정해진 시간에 앞서 준비한 함수를 실행시키도록 하는 것도 가능합니다. schedule 라이브러리 같은 것을 사용하면 되겠죠. 하지만 그런 환경이 마련되지 않는다면, 이걸 굳이 로컬에서 돌리지 않아도 외부 클라우드에 올려서 돌리는 것도 가능합니다. 이 글에서는 아마존 AWS를 활용해 클라우드에 코드를 올리고, 자동으로 정해진 시각에 실행시키도록 설정하는 방법을 알아보고자 합니다.
먼저 아마존 AWS에 아직 가입되어있지 않다면 프리 티어로 가입합니다. 웬만한 서비스들은 바로 무료로 사용이 가능하지만 카드 번호는 입력해야하고 일부 서비스는 무료 기간이 끝나면 과금이 될 수 있으니 주의해야 합니다. AWS에 로그인하고 나면 좌상단의 검색창으로 AWS의 서비스들을 검색할 수 있습니다. 아마존에서 제공하는 무수히 많은 앱들 중에서 저희가 여기에서 살펴볼 것들은 다음과 같은 네 가지입니다.
- AWS Lambda: 클라우드 서버에서 코드를 실행시켜줍니다.
- AWS EventBridge: AWS Lambda에 올린 함수를 정해진 시간에 실행시켜줍니다.
- AWS S3: 파일을 저장하고 불러올 수 있는 저장소입니다.
- AWS DynamoDB: 작은 사이즈의 DB를 돌릴 수 있습니다.
가장 기본적이며 중요한 서비스들은 AWS Lambda와 AWS EventBridge이고, 모니터링할 때 AWS CloudWatch가 필요한 정도입니다. 나머지 둘은 어떤 봇을 돌릴지에 따라 필요할 수도 있고 안 할 수도 있죠. 이들에 대해서 차례대로 알아보도록 하겠습니다.
3. AWS Lambda에 코드 올리기
AWS 서비스 검색창에 Lambda라고 치면 해당 서비스로 빨리 이동할 수 있습니다. 그러면 아래와 같은 화면이 뜰 것입니다.

여기서 오른쪽 위 “함수 생성”을 눌러 함수를 추가해줍니다.

“새로 작성”을 선택해 함수 이름을 입력하고, 런타임에서 Python을 선택합니다. 아키텍처는 x86_64를 선택해도 무방합니다. 나머지는 여기서는 따로 건드리실 필요는 없을 것입니다. 바로 우하단의 “함수 생성”을 눌러줍니다.

그러면 드디어 코드를 입력할 수 있는 창이 뜹니다. 디폴트 설정으로 이 lambda_function.py의 lambda_handler란 함수가 실행하게 될 목적 함수가 됩니다. 만약 실행시키고자 하는 코드가 py 파일 하나 안에 들어간다면 이 창에 바로 복붙해서 실행시킬 함수 이름을 바꾸거나, 아래의 런타임 설정에서 핸들러를 코드에 맞게 바꿔 설정해주면 됩니다. 만약 여러 파일이 필요하다면, 그 파일들을 zip으로 압축해 우상단의 “에서 업로드”를 눌러 업로드하면 됩니다. 참고로 만약 이 창에서 코드를 수정하게 된다면 수정할 때마다 반드시 위의 Deploy 버튼을 눌러야 그 내용이 적용되니 주의하시기 바랍니다.
여기서 Test 버튼을 누르고 대충 이벤트 이름 입력해서 바로 실행해볼 수 있습니다. 아마 웬만하면 이 단계에서 에러가 뜰텐데, 파이썬만 설치되어있고 다른 외부 라이브러리가 하나도 안 깔려있는 상태이기 때문일 것입니다. (No module named 어쩌구 에러) 이걸 해결하기 위해서는 레이어(계층)를 깔아야 합니다. 레이어는 말 그대로 현재의 상태에 추가로 어떤 파일들이 올라가 있는 것이라고 간단히 설명할 수 있는데, 먼저 로컬에서 python이란 폴더를 만들고 그 폴더 상에서 커맨드 창이나 파워셸로 다음과 같이 실행합니다.
pip install (라이브러리 이름) -t .그러면 그 폴더 내에 site-package에 있을 내용들이 설치가 됩니다. 이제 python 폴더를 통째로 zip으로 압축합니다. 이것이 레이어를 구성하게 될 것입니다. 레이어를 사용하지 않고 앞에서 코드를 업로드할 때 같이 zip 파일로 묶어서 업로드해도 가능하지만 이렇게 레이어를 활용하는 편이 라이브러리 관리 측면에서 더 편리할 것입니다.
다시 AWS Lambda 창으로 돌아와서, 맨 밑의 “계층 추가”를 누르고, 왼쪽 탭에서 “계층”을 선택합니다.
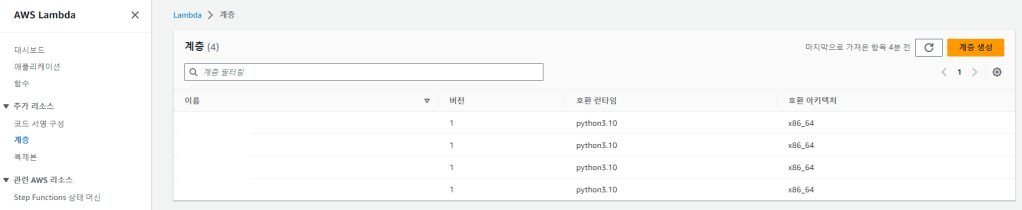
그 상태에서 우상단 “계층 생성”을 누르면 계층을 구성할 수 있는데, 이름을 입력하고, 업로드하고, x86_64 선택하고, 런타임에서 파이썬 선택하고, “생성”을 눌러서 레이어를 등록할 수 있습니다. 다시 방금 전과 같이 “계층 추가”를 눌러 아래와 같은 화면으로 돌아갑니다.

여기서 “사용자 지정 계층”을 선택하면 방금 등록한 레이어를 선택할 수 있게 됩니다. 선택 후 “추가”를 눌러주면 이제 코드 실행에 필요한 라이브러리를 import할 수 있게 됩니다. Test를 몇 번 거쳐서, 코드를 문제 없이 실행할 수 있는 상태가 되면 다음으로 넘어갑니다.
4. AWS EventBridge에서 스케줄 설정하기
이제 스케줄을 설정하기 위해 AWS EventBridge 서비스를 이용해봅시다.

메인 페이지에서 위와 같이 “EventBridge 일정”을 생성합니다. 다음 화면에서 이름을 설정하고, 발생을 “반복 일정”으로 설정합니다. 그러면 Cron 형식 혹은 Rate 형식으로 언제 실행시킬지 일정을 설정할 수 있습니다. Cron은 연월일시분 단위로 조건을 주는 식이고, Rate는 단순히 매 몇 분 혹은 몇 시간마다 실행시킬지를 설정하는 식입니다. 유연한 기간은 ‘꺼짐’으로 해도 되고, 시간대는 알아서 한국 시간대로 설정되어있을 것입니다. 아닐 경우 UTC+09:00을 선택합니다.
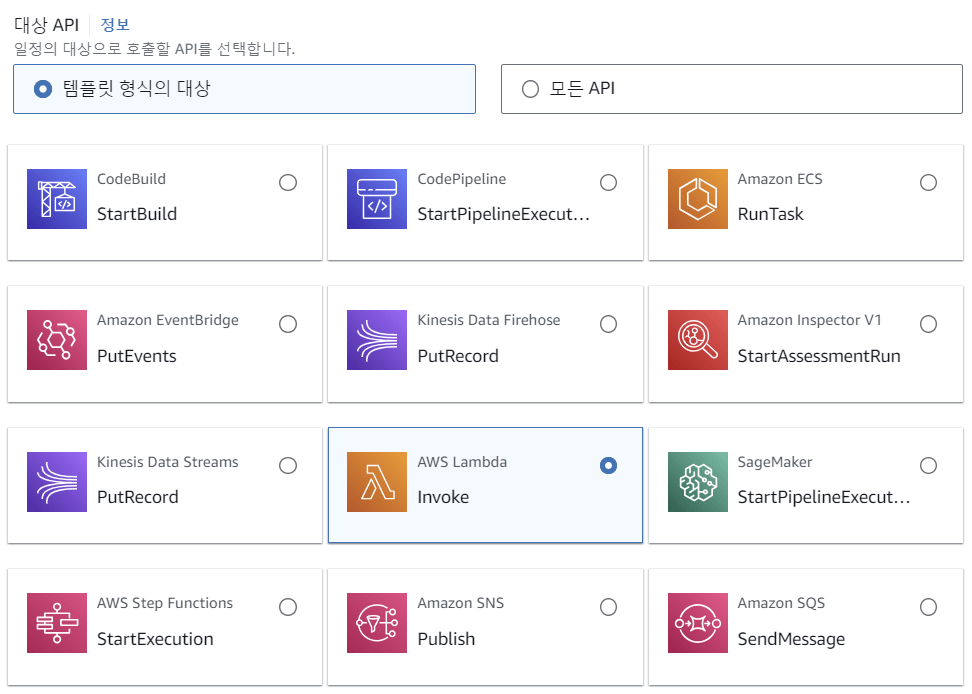
다음 화면에서는 위와 같이 AWS Lambda Invoke를 선택합니다. 그러면 아래에서 Lambda의 어느 함수를 실행시킬 지를 선택할 수 있습니다. 그 이후는 적절히 대충 선택하면 됩니다. 이렇게 스케줄러를 설정하면 원하는 시간에 함수가 자동으로 실행되도록 할 수 있습니다. 자동화 봇을 돌리기 위한 기초적인 내용은 이것으로 끝입니다.
5. AWS S3로 저장소 사용하기
하지만 간혹, 파일을 저장해야 할 필요성이 있을 수 있습니다. 예컨대 외부에서 사진을 받아온 후 그것을 파일로 저장해 포스트에 첨부한다든지, 오픈 API에서 조회한 것들 중 이미 포스트한 것을 제외하기 위해 기존에 포스트한 이력을 저장한다든지… (사실 전자 같은 경우는 파일로 저장하지 않아도 되긴 하고, 후자 같은 경우는 DB를 사용하면 더 간단하게 해결될 수 있겠지만요)
만약 로컬에서 하던대로 파일 저장하고 불러오는 코드를 짜서 실행을 시키면 권한 문제가 발생할 것입니다. AWS Lambda는 기본적으로 모든 파일이 전부 읽기 전용입니다. 한 가지 예외로 /tmp/ 디렉토리 내의 파일들은 자유롭게 저장하고 불러올 수 있지만, 이 디렉토리는 임시적인 것이라 내용물이 언젠가 삭제되는 것이 전제됩니다. 이 시점에서 S3를 활용해 파일을 저장하고 불러오는 방법을 알아보도록 합니다.

S3 페이지로 들어가서, 먼저 “버킷 만들기”를 선택해 버킷을 만듭니다. 버킷은 스토리지의 가장 큰 구분 단위라고 보시면 될 것 같습니다. 그 후 이름을 입력하고 버킷 버전 관리를 활성화, 기본 암호화를 활성화로 맞춥니다. 나머지는 그대로 둬도 무방할 것입니다.

이렇게 마련한 저장소를 AWS Lambda에서 활용하려면 권한 문제를 먼저 해결해야 합니다. 이를 위해, 역할을 관리하는 AWS 서비스인 AWS IAM으로 이동하여 왼쪽 탭에서 역할을 선택한 후, 우상단 “역할 만들기”를 선택합니다.
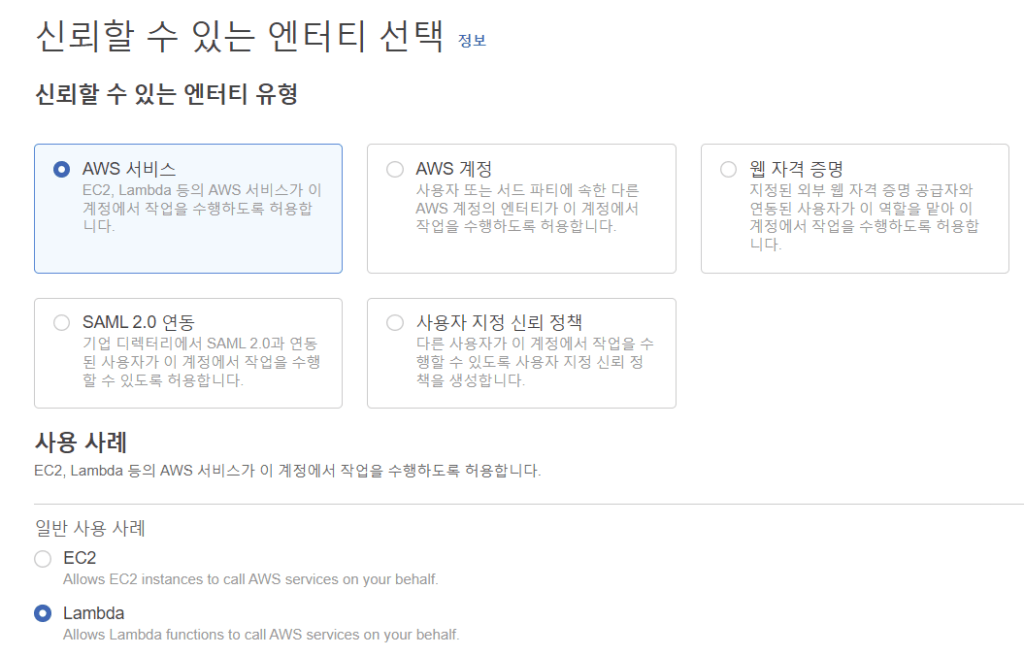
다음 화면에서는 AWS 서비스, Lambda를 선택합니다. 그러면 검색창이 뜨는데 여기서 AmazonS3FullAccess를 선택해 역할 이름을 지정하면 S3에 대해 모든 권한을 갖는 역할을 만들 수 있습니다.

이제 Lambda에서 돌리고자 하는 함수의 “구성” 탭을 선택하고 “편집”을 눌러, 역할을 아까 지정한 이름의 역할로 설정하면 됩니다. 이로써 Lambda에서 S3에 대한 권한 문제는 해결됩니다.
코드 상에서 해당 버킷의 파일을 다루기 위해서는 아래와 같은 함수들을 짜서 활용해볼 수 있겠습니다. 이렇게 S3에 파일을 쓰고, S3에 있는 파일을 읽거나 지우는 것이 가능하게 됩니다.
import boto3
import pickle
BUCKET = (버킷 이름)
s3 = boto3.client('s3')
def upload_file_s3(filename, file):
encode_file = bytes(pickle.dumps(file))
s3.put_object(Bucket=BUCKET, Key=filename, Body=encode_file)
def read_file_s3(filename):
file = s3.get_object(Bucket=BUCKET, Key=filename)["Body"].read()
return pickle.loads(file)
def delete_file_s3(filename):
s3.delete_object(Bucket=BUCKET, Key=filename)6. AWS DynamoDB로 데이터베이스 관리하기
# to-do
7. 더 읽어볼 것들
- AWS Lambda에서 AWS S3 파일 읽어오는 방법: Lambda와 S3를 연동하는 방법을 설명한 가이드입니다.
- [初心者向け]たった50行のコードでTwitter Botを作成してみる: (일본어) AWS를 활용해 트위터 봇을 만드는 방법을 설명한 가이드입니다.
- 파이썬 네이버 뉴스 크롤링해서 텔레그램 보내는 코드 – 크롤링을 이용해 자동화 봇을 만드는 예시입니다.
- 키움증권 OpenApi + 텔레그램 봇 조건검색식 실시간 알람기 파일 – 타사 오픈API를 이용해 자동화 봇을 만드는 예시입니다.

“파이썬으로 블루스카이 봇 만들기”의 2개의 생각