이전 글 “랜덤 워드에서 특정 워드가 등장할 확률“이 수학동아의 폴리매스 프로젝트에 링크된 것을 확인했다. 국가수리과학연구소의 2번째 문제의 추가 문제 2번 문제가 다음과 같다고 한다.
길이  짜리 단어
짜리 단어 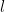 하나가 금칙어로 지정되었을 때, 길이
하나가 금칙어로 지정되었을 때, 길이  짜리 단어 중 이를 포함하지 않는 것의 개수를
짜리 단어 중 이를 포함하지 않는 것의 개수를 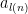 이라고 합시다. 이 고정되어 있을 때, 이 무한대로 갈 때
이라고 합시다. 이 고정되어 있을 때, 이 무한대로 갈 때  의 극한이 최대/최소가 되는 은 각각 어떻게 주어질까요?
의 극한이 최대/최소가 되는 은 각각 어떻게 주어질까요?
앞서 이야기한 논의에서 조금 더 연장하면 이 문제 역시 해결될 수 있다. 참고로 위 문제에서는 알파벳 집합  가
가  로 주어져 있는데 그냥 일반적인 경우로 봐
로 주어져 있는데 그냥 일반적인 경우로 봐  라고 둔다.
라고 둔다.
이전 글에서는 특정 워드 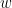 가 하나라도 포함될 확률에 대해서 다뤘다. 결과를 요약하자면 길이가 인 uniform random word에서 길이 인 특정 워드가 등장할 확률을 구하기 위해서
가 하나라도 포함될 확률에 대해서 다뤘다. 결과를 요약하자면 길이가 인 uniform random word에서 길이 인 특정 워드가 등장할 확률을 구하기 위해서  개의 state들로 구성된 Markov chain을 만들고 이것의 transition matrix(stochastic matrix)의 특성방정식을 구한 후, 그 해를 편의상
개의 state들로 구성된 Markov chain을 만들고 이것의 transition matrix(stochastic matrix)의 특성방정식을 구한 후, 그 해를 편의상  라고 하면 (
라고 하면 ( 는 multiplicity) 구하고자 하는 확률은 반드시
는 multiplicity) 구하고자 하는 확률은 반드시  꼴로 나타난다는 것이다. (단,
꼴로 나타난다는 것이다. (단,  이며
이며  는 차수가 보다 작은 다항식이다)
는 차수가 보다 작은 다항식이다)
이 결과를 응용하면 가 포함되지 않는 확률은 1에서 이 값을 빼야 하므로 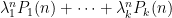 꼴로 나타나는데, 애초에 랜덤 워드가 균일하게 뽑혔던 것이므로 문제에서 요구하는 경우의 수 은 그 확률에
꼴로 나타나는데, 애초에 랜덤 워드가 균일하게 뽑혔던 것이므로 문제에서 요구하는 경우의 수 은 그 확률에  을 곱한 꼴이 되어야 한다. 따라서 1을 제외한 eigenvalue들 중 절대값이 가장 큰 것을
을 곱한 꼴이 되어야 한다. 따라서 1을 제외한 eigenvalue들 중 절대값이 가장 큰 것을  라 두면
라 두면 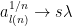 가 된다.
가 된다.
편의상 우리가 지금까지 생각한 transition matrix를  라 하고,
라 하고,  로 정의한다. 이
로 정의한다. 이 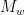 는 모든 항이 정수로 등장하며, eigenvalue가 의 eigenvalue에
는 모든 항이 정수로 등장하며, eigenvalue가 의 eigenvalue에  를 곱한 꼴들로만 나오니 문제에서 묻는 극한은 바로 의 second large eigenvalue가 된다.
를 곱한 꼴들로만 나오니 문제에서 묻는 극한은 바로 의 second large eigenvalue가 된다.
이전 글에서 확률을 계산할 때 포함과 배제의 원리를 이용한 풀이를 보았는데, 그 풀이는 일반적인 답을 주지는 못했지만 굉장히 중요한 점을 하나 시사하고 있다. 그것은 포함과 배제의 원리 풀이가 적용되는 경우, 즉 가 겹쳐서 나타날 수 없는 경우라면 그 확률(혹은 경우의 수)은 일정하게 나와야 한다는 것이다. 당연한 것처럼 보이지만 Markov chain 관점에서는 그게 trivial하지가 않다. 예를 들어, 이전 글의 예시의 경우 ( ) AUG와 AAU는 그 Markov chain의 구조가 달라져서 행렬들 역시
) AUG와 AAU는 그 Markov chain의 구조가 달라져서 행렬들 역시
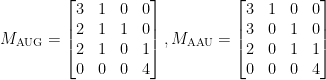
로 다르게 나오는데, 특성방정식은 동일하게  로 나타난다. 포함과 배제의 원리로 생각하면 AUG든 AAU든 단어 내부의 구조만 동일하다면 디테일과 상관없이 결과가 동일하게 나오는 것.
로 나타난다. 포함과 배제의 원리로 생각하면 AUG든 AAU든 단어 내부의 구조만 동일하다면 디테일과 상관없이 결과가 동일하게 나오는 것.
포함과 배제의 원리 풀이가 적용되지 않는 것은 가 겹쳐서 나타날 수도 있다는 것이었는데, 그러면 구체적으로 가 얼마나 겹쳐서 나타날 수 있는지를 따져본다. 예컨대 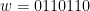 이었다면, 4번째 포지션부터 시작되는 와도 겹칠 수 있고, 7번째 포지션부터 시작되는 와도 겹칠 수 있다. 그런데 가 서로 겹치는건 곧 가 순순환이란 것을 의미한다. (첫 번째 포지션부터
이었다면, 4번째 포지션부터 시작되는 와도 겹칠 수 있고, 7번째 포지션부터 시작되는 와도 겹칠 수 있다. 그런데 가 서로 겹치는건 곧 가 순순환이란 것을 의미한다. (첫 번째 포지션부터  번째 포지션까지의 부분이 되풀이해서 등장함) 그러한 (최소의) 순환주기 를 잡으면, 곧 는 1번째,
번째 포지션까지의 부분이 되풀이해서 등장함) 그러한 (최소의) 순환주기 를 잡으면, 곧 는 1번째,  번째,
번째, 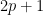 번째, …에서 시작하는 들과만 겹치는 것을 확인할 수 있다. (위 예시의 경우
번째, …에서 시작하는 들과만 겹치는 것을 확인할 수 있다. (위 예시의 경우  ) 참고로 앞서 본 가 항상 겹치지 않는 “복잡하지 않은” 경우는
) 참고로 앞서 본 가 항상 겹치지 않는 “복잡하지 않은” 경우는 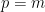 으로 둔다.
으로 둔다.
그러면  인 경우
인 경우  같은 값은 조금 더 복잡하게 수정되어야 하는데, 여기서 앞서 눈여겨본 이 풀이의 장점, 즉 의 구조만 같다면 그 식은 동일하게 나온다는 원리를 또 다시 적용할 수 있다. 즉, 만약 두 워드
같은 값은 조금 더 복잡하게 수정되어야 하는데, 여기서 앞서 눈여겨본 이 풀이의 장점, 즉 의 구조만 같다면 그 식은 동일하게 나온다는 원리를 또 다시 적용할 수 있다. 즉, 만약 두 워드 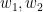 가 같은 순환주기 를 갖는다면 이 둘에 대한 는 뭔가 복잡한 꼴이 되겠지만 확실한건 이들이 일치한다는 것이다. 이는 물론
가 같은 순환주기 를 갖는다면 이 둘에 대한 는 뭔가 복잡한 꼴이 되겠지만 확실한건 이들이 일치한다는 것이다. 이는 물론  이후의 항들에 대해서도 마찬가지. 예컨대 두 단어가 AUUA일 때와 UCGU일 때 둘 다
이후의 항들에 대해서도 마찬가지. 예컨대 두 단어가 AUUA일 때와 UCGU일 때 둘 다 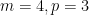 인 경우로 일치하기 때문에 포함과 배제의 원리에 등장하는 식들이 전부 일치하게 되어 같은 확률(경우의 수)을 갖게 된다.
인 경우로 일치하기 때문에 포함과 배제의 원리에 등장하는 식들이 전부 일치하게 되어 같은 확률(경우의 수)을 갖게 된다.
따라서, 만약 의 길이가 , 순환주기가 로 주어졌다면  라 할 때 와
라 할 때 와  는 같은 특성방정식을 얻게 된다. 이 행렬의 경우
는 같은 특성방정식을 얻게 된다. 이 행렬의 경우 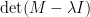 를 Gauss elimination으로 쉽게 구할 수 있고, 그 결과 다음과 같은 결과를 얻는다.
를 Gauss elimination으로 쉽게 구할 수 있고, 그 결과 다음과 같은 결과를 얻는다.
Proposition. 의 길이가 , 순환주기가 라면 의 특성방정식은  가 된다.
가 된다.
위에서 등장한 다항식들은 전부 보다 약간 작은 실수해를 하나 갖는데, 이게 를 제외하고 절대값이 최대인 해임을 확인할 수 있다. 이 결과를 이용해서 고려해야할 개의 다항식들의 최대해를 비교하면, 문제에서 요구하는 극한이 최대인 경우는 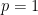 (
(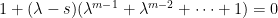 의 최대의 실수해), 최소인 경우는 (
의 최대의 실수해), 최소인 경우는 ( 의 최대의 실수해)인 것을 확인할 수 있게 된다.
의 최대의 실수해)인 것을 확인할 수 있게 된다.

“랜덤 워드에서 특정 워드가 등장할 확률 (2)”의 1개의 생각