zariski님의 블로그의 글에 언급된 naturale님의 글을 읽고.
전체
ntd로 이루어진 target RNA 한 가닥이 있다고 하자. 이 RNA는 완전히 랜덤하게 만들어진 가닥이라고 가정한다. 즉, 각 위치에 A, U, G, C가 같은 확률로 존재할 수 있다.
이제
-mer sequence motif가 하나 있다고 하자. 이 sequence motif는 특정되어 있다.
이 때 Target RNA 가닥에서 이 motif가 한 번이라도 등장할 확률은 얼마일까?
즉 알파벳 집합의 크기가 4이고 길이가 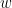
naturale님의 포함-배제의 원리를 이용한 풀이는 많은 경우 옳지만, 일부 워드의 경우 정확한 확률값과 맞아떨어지지는 않는다. 이 풀이대로라면 처음에 주어지는 워드가 어떻게 주어지더라도 그 확률은 동일하게 나와야 한다. 하지만 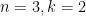


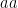



이것은 
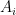
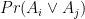



그래서 일반적인 경우를 따지기 위해서는 다른 방법론이 좋은데, 여기서는 Markov chain을 이용하는 것을 설명하고자 한다. (기본적으로 naturale님이 말미에 언급한 DFA(deterministic finite automata) 모델과 대동소이) 쉽게 표현하자면 유한개의 state들을 잡고 한 state에서 다른 state으로 가는 확률을 지정하는 모델을 뜻한다. 원래 문제처럼 알파벳 집합이 A, U, G, C로 주어져 있고, 여기서 길이 3인 워드 AUG가 등장할 확률을 구하는 것을 생각해본다.
이제 비어있는 워드 
- State 1: 현재 완성되어있는 워드가 A로 끝난다.
- State 2: 현재 완성되어있는 워드가 AU로 끝난다.
- State 3: AUG를 찾았다. (PROFIT!)
- State 0: 이도저도 아니다.
여기서 초기 워드
- State 0에서 다음에 올 값이 A이면 State 1으로 가고,(확률 1/4) 아니면 계속 State 0에 머문다.(확률 3/4)
- State 1에서 다음에 올 값이 A이면 머무르고,(확률 1/4) U이면 State 2로 가고,(확률 1/4) 둘 다 아니면 State 0로 간다.(확률 1/2)
- State 2에서 다음에 올 값이 A이면 State 1으로 가고,(확률 1/4) G이면 State 3로 가고,(확률 1/4) 둘 다 아니면 State 0로 간다.(확률 1/2)
- State 3에서는 무조건 다시 State 3로 간다.(확률 1)
이 확률들을 행렬로 표현해, State 

가 된다. 이 transition matrix가 왜 유용하냐면, 

AUG는 앞서 언급한 “복잡하지 않은” 경우에 해당되며, 그렇지 않은 경우라면 transition matrix는 조금 다르게 나타난다. (state 개수는 똑같이 4개로 구현할 수 있다) 예컨대 만약

이 된다.
그래서 구하고자 하는 확률은 



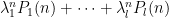



Wolfram Alpha의 계산에 의하면 AUG 케이스의 transition matrix의 특성방정식은 
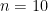

설명 감사합니다. ㅎㅎ 찾으려는 motif에 따라 확률이 조금씩 차이가 나겠군요. 생각이 미치지 못했습니다. 감사합니다.
좋아요좋아요
넵, 마지막 문단에 AUA의 케이스를 추가했는데 조금 차이가 나타나게 됩니다. 더불어 부가적으로, 각 state에 해당하는 길이 m의 중간 워드의 개수를 각각 수열로 정의하여 정리하면 연립 선형 점화식이 되고 이를 정리해서 State 3에 대한 수열로만 표현할 수 있는 선형 점화식 꼴로 바꾸는 것도 가능하며 그 때도 같은 특성 방정식을 얻게 됩니다.
좋아요좋아요
설명 감사합니다. 많이 배웁니다. 🙂
좋아요좋아요